
AI进入推理模型时代,一文带你读懂思维链
AI进入推理模型时代,一文带你读懂思维链近段时间,推理模型 DeepSeek R1 可说是 AI 领域的头号话题。用过的都知道,该模型在输出最终回答之前,会先输出一段思维链内容。这样做可以提升最终答案的准确性。
来自主题: AI技术研报
9470 点击 2025-03-16 14:53
近段时间,推理模型 DeepSeek R1 可说是 AI 领域的头号话题。用过的都知道,该模型在输出最终回答之前,会先输出一段思维链内容。这样做可以提升最终答案的准确性。

尽管 DeepSeek-R1 在单模态推理中取得了显著成功,但已有的多模态尝试(如 R1-V、R1-Multimodal-Journey、LMM-R1)尚未完全复现其核心特征。

据外媒 TechCrunch 报道,OpenAI 近日在一项新的政策提案中,将 DeepSeek 描述为被官方资助和控制的实体,并呼吁对该机构及类似机构开发的中国 AI 模型实施禁令。OpenAI 在提案中指出:「虽然目前美国在 AI 领域仍保持领先,但 DeepSeek 的出现表明,这一领先优势并不大,且正在缩小。」
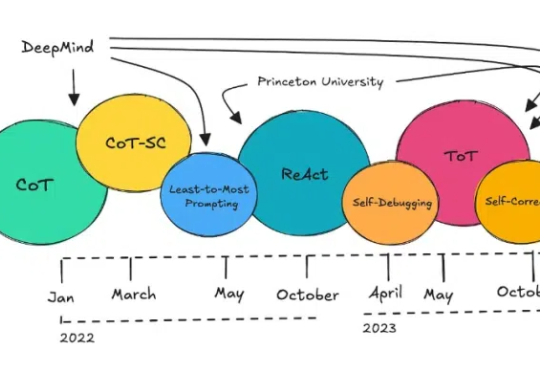
近年来,大语言模型(LLM) 的快速发展正推动人工智能迈向新的高度。像 DeepSeek-R1 这样的模型因其强大的理解和生成能力,已经在 对话生成、代码编写、知识问答 等任务中展现出了卓越的表现。
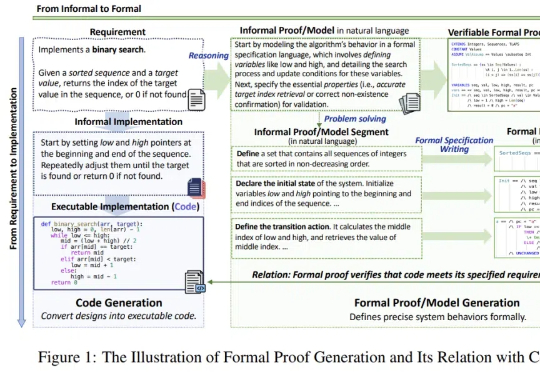
随着 DeepSeek-R1 的流行与 AI4Math 研究的深入,大模型在辅助形式化证明写作方面的需求日益增长。作为数学推理最直接的应用场景,形式化推理与验证(formal reasoning and verification),也获得持续关注。
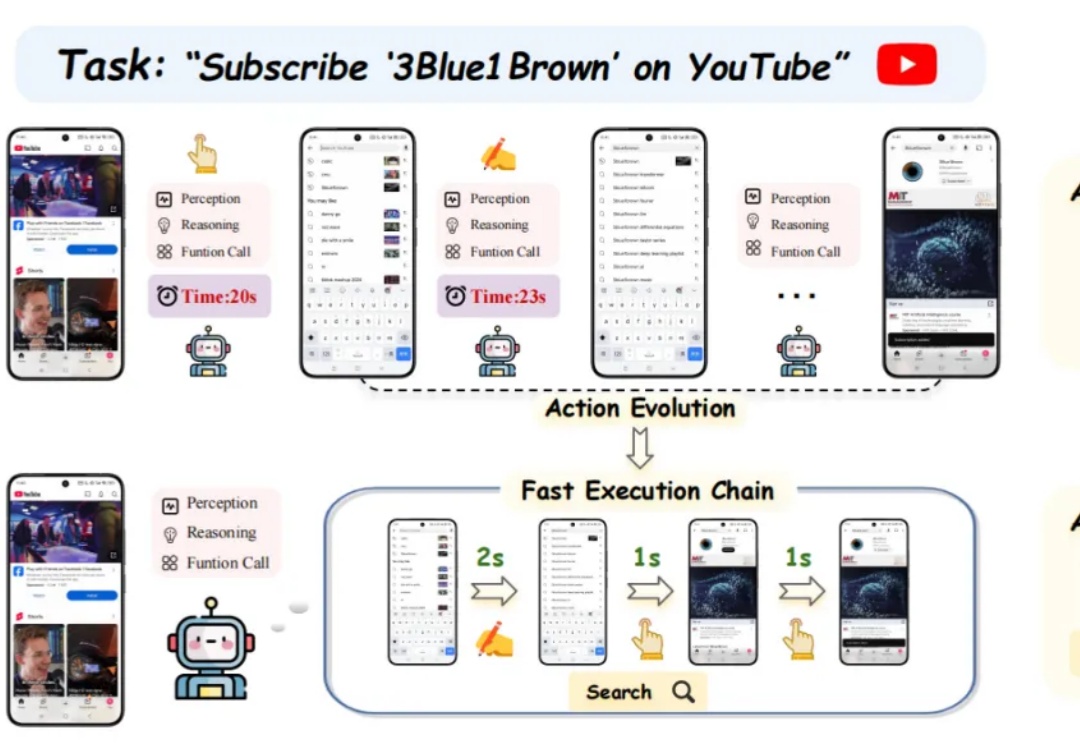
仅仅过了一天,阿里开源的新一代推理模型便能在个人设备上跑起来了!昨天深夜,阿里重磅开源了参数量 320 亿的全新推理模型 QwQ-32B,其性能足以比肩 6710 亿参数的 DeepSeek-R1 满血版。

让人感到非常费解的是,在这些媒体口中如此“王炸”的 AI 突破,在海外几乎没有什么讨论,这与 DeepSeek 墙内开花墙外香,海外各路 AI 大神们甘当自来水疯狂吹爆的现象形成了巨大的反差
如果根据AI自媒体们的标题来看,昨天全世界AI圈应该无人存活,因为他们又被“炸”了。

编辑注:今天上线的Manus引发了全网的 Agent 热潮,Manus 背后的产品团队——Monica.im 的产品团队也引起了大家的关注。Manus产品负责人张涛在 2 月份曾经有过一次公开分享,解读 DeepSeek R1 成功背后的技术进步和产品思路,从中可以一窥 Manus 的部分解题思路。

又一个「DeepSeek 王炸组合」,来了。2 月 28 日,两个国民级应用,百度文库和百度网盘,全量接入了 DeepSeek-R1 满血版。